Pandas is very widely used Python library for data manipulation and analysis. It allows to load data in a tabular format to manipulate it for different analysis and graphical presentation. DataFrame is the key data structure in Pandas to perform tabular operations. First step while analyzing data with Pandas is to read a file and load it into Pandas DataFrame. Pandas supports data load from various file formats e.g. csv, excel, flat file, JSON, parquet, SQL, etc. Most of the times, the data file can be locally available. However, with cloud infrastructure, the files are now a days securely stored in a blob or loaded into an encrypted database. This post provides the steps to read data from Azure to Pandas DataFrame, mainly from Azure Blob Storage, Cosmos DB and Application Insights
Prerequisites
- Experience with Python programming language (Python3)
- Basic understanding of Pandas APIs
- Experience with Jupyter and access to an instance of Notebook/Lab
- Access to Azure Cloud
1. Read from Azure blob storage
A simple use case is to read a csv or excel file from Azure blob storage so that you can manipulate that data. Microsoft document provides one way to achieve that, download the file locally and then read it. In my experience, this can result into a security risk if the data is either personal or financial. Organizations protect this sensitive information because there are many global regulations. So the other option is to read the file directly from blob storage into Pandas DataFrame
To read the file directly from blob storage, create SAS token and append it to the file’s blob URL
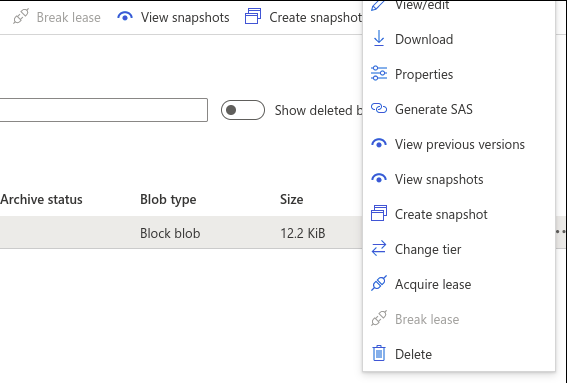
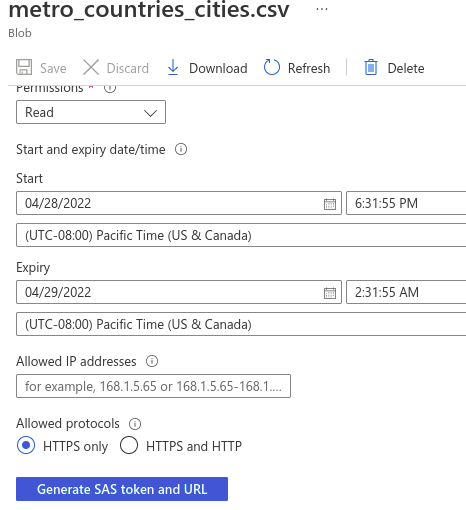
Once you have the ‘Blob SAS URL’, go to your Jupyter Notebook/Lab instance and create a settings JSON file. This settings file can be similar to the one created by Azure functions to maintain local settings. You should never check-in settings file to Git repo because it has keys and connection strings. In the settings file, add a new key for the Blob SAS URL
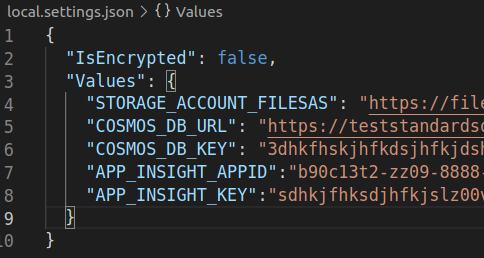
Open the notebook, read the SAS URL from the local settings and read it into Pandas DataFrame
from json import load
settings = load(open('local.settings.json', 'r'))['Values']
fileurl = settings['STORAGE_ACCOUNT_FILESAS']Code language: JavaScript (javascript)import pandas as pd
df = pd.read_csv(fileurl)Code language: JavaScript (javascript)2. Read from Azure Cosmos DB
When I wanted to read data from Azure Cosmos DB to Pandas, I started searching for a SQLAlchemy adapter (Dialect) for Cosmos DB. However, after researching, I found that it will be possible to just use Python APIs provided by Azure. To start, you can continue to use local settings file to store Cosmos DB connection strings
Open the notebook, read the Cosmos DB URL and key from the local settings and read a container data into Pandas DataFrame
from json import load
settings = load(open('local.settings.json', 'r'))['Values']
url = settings['COSMOS_DB_URL']
key = settings['COSMOS_DB_KEY']Code language: JavaScript (javascript)from azure.cosmos import CosmosClient
client = CosmosClient(url, credential=key)
database_name = 'stdsql'
database = client.get_database_client(database_name)
container_name = 'stdsql'
container = database.get_container_client(container_name)Code language: JavaScript (javascript)import pandas as pd
df = pd.DataFrame(container.read_all_items())Code language: JavaScript (javascript)If you want to read selected data using SQL query, use query items,
df = pd.DataFrame(container.query_items('select * from c'
,enable_cross_partition_query=True))Code language: PHP (php)Cosmos DB maintains system level fields for every document in the database container. These fields start with an underscore. You can remove it from the DataFrame so that the data is cleaner to start the analysis
df = df.loc[:,~df.columns.isin(['id','_rid', '_self', '_etag', '_attachments', '_ts'])]Code language: JavaScript (javascript)3. Read from Azure Application Insights
Azure Application Insights allows to review logs for various services. This is very useful for the troubleshooting and debugging. If you have accessed logs in the application insights, you must know that the log information is queried using KQL. Azure provides an extension for Jupyter so that you can read the insights data in the Pandas DataFrame to use the power of Pandas
Open the notebook and install ‘kqlmagic’ Python package
%%capture --no-display
%pip install Kqlmagic --no-cache-dir --upgrade;The first line in the notebook cell ensures that output of the installation is not displayed in the result. The code in this cell will make sure that kqlmagic extension is up to date. Reload the extension as a next step so that latest version is available for the session
%%capture --no-stdout
%reload_ext KqlmagicRead the Application Insights ‘Application Id’ – ‘Key’ from the local settings and connect to your instance on Azure
from json import load
settings = load(open('local.settings.json', 'r'))['Values']
appid = settings['APP_INSIGHT_APPID']
appkey = settings['APP_INSIGHT_KEY']Code language: JavaScript (javascript)%kql appinsights://appid=appid;appkey=appkeyCode language: JavaScript (javascript)At this point, you should be able to form any KQL query to read data from the insights and load into Pandas DataFrame
%%capture --no-stdout
#read all the traces or form a kql query with parameters
%kql tracesCode language: PHP (php)df = _.to_dataframe()If you noticed, the DataFrame here is created from an underscore object. This is as per ‘kqlmagic‘ documentation and it is because the extension creates anonymous object for ‘%kql’ command