Azure Data Factory is a cloud hosted ETL (Extract, Transform, Load) service provided by Microsoft Azure. It allows to connect to wide variety of systems, transform that information and load it. The service is Serverless, highly scalable and can support processing large amount of data. When you initially develop a data flow, the processing engine is setup with few default settings that can be changed for performance optimization in Azure Data Factory. This post describes few tips and tricks that can be useful to optimize performance in Azure Data Factory
Problem statement
Connect to a source, extract the data, transform the data and load it into a destination through Azure Data Factory. It is taking x minutes to execute the flow in ADF. There is a requirement to reduce the execution time so the job finishes in a described SLA (Service Level Agreement)
Step 1: Prerequisites
- Access to Azure cloud
- A data source and sink
- A Pipeline with a Data flow in Azure Data Factory
Step 2: Optimize the default runtime
When you develop a pipeline with a data flow in ADF, the service creates default runtime so it can launch your ETL process when you select to execute the pipeline. To review the default runtime, go to ADF -> Monitor -> Integration runtimes
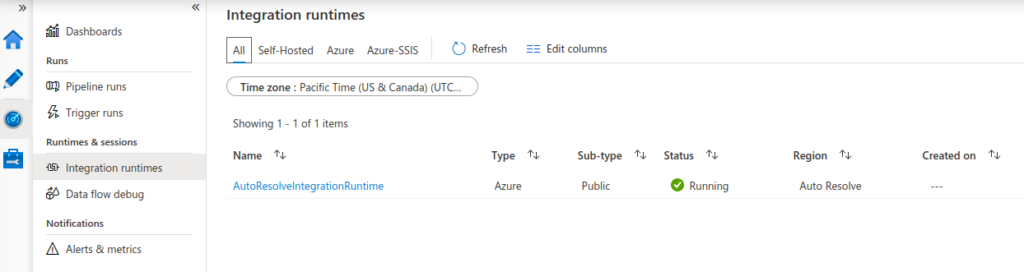
To review this runtime, go to ADF -> Author -> Pipeline -> Dataflow -> Run On
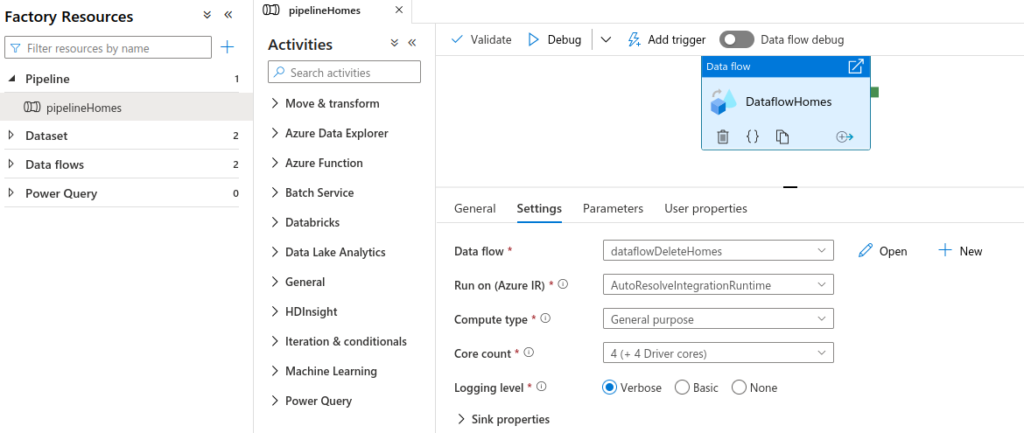
Optimize the default runtime by selecting appropriate Compute type (General purpose / Memory Optimized) and Core count (4 to 256). Also, select either Basic or None as Logging level for the production system so that logging takes lower time resulting into better performance
Step 3: Create a custom runtime
Even with improved default runtime performance as described in the step 2 above, there is still some room to optimize overall execution time. When you select to execute a pipeline in ADF, the service takes some time to launch the runtime, cluster startup time. To review Cluster startup time, go to All pipeline runs -> Data flow -> Data flow details
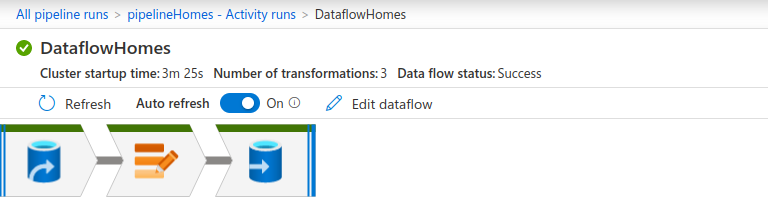
To improve the cluster startup time, create a custom integration runtime. Go to ADF -> Manage -> Integration runtimes -> New
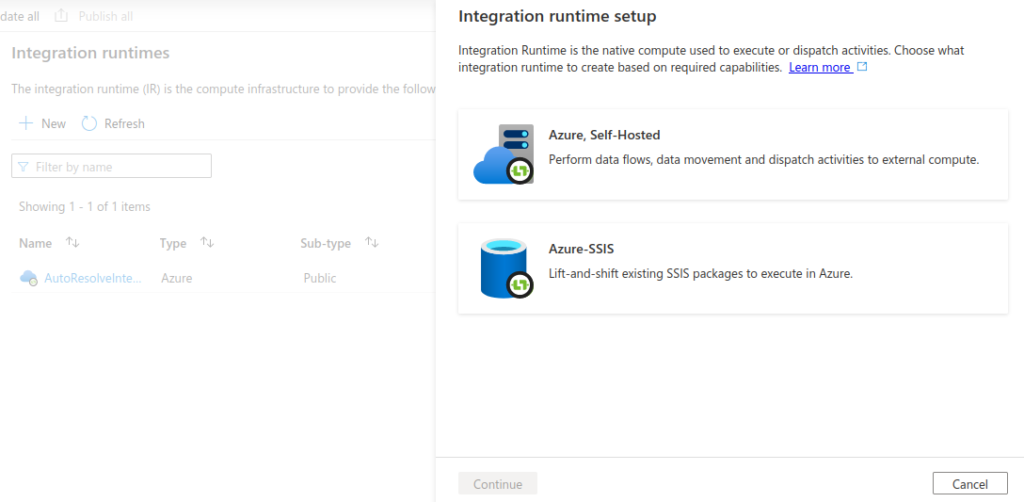
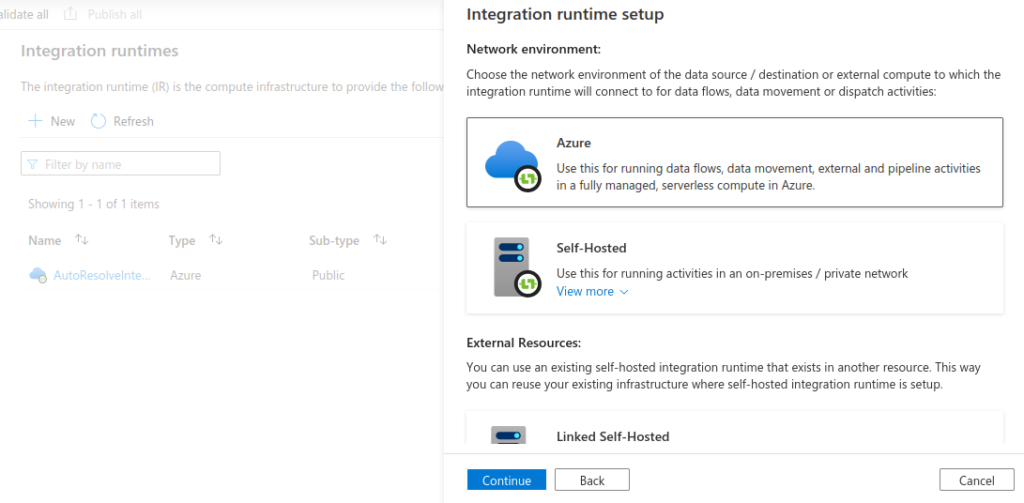
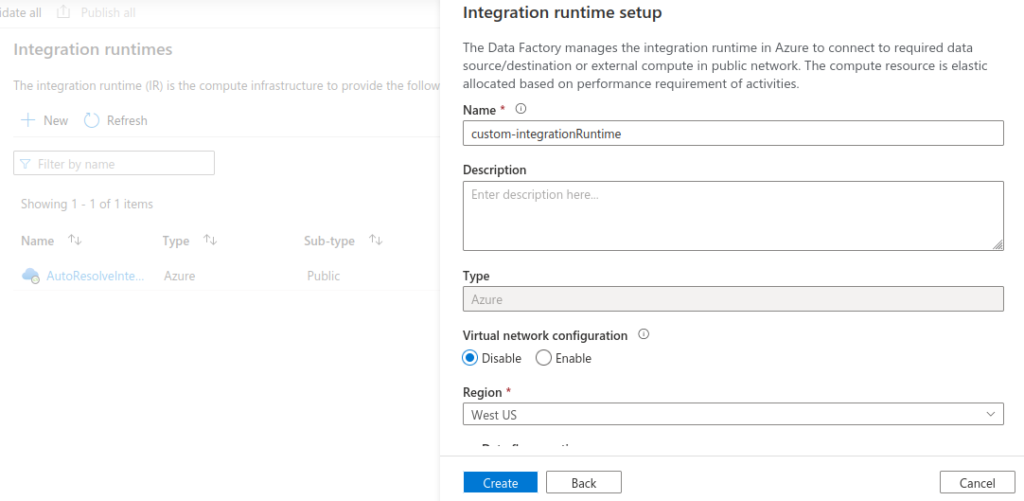
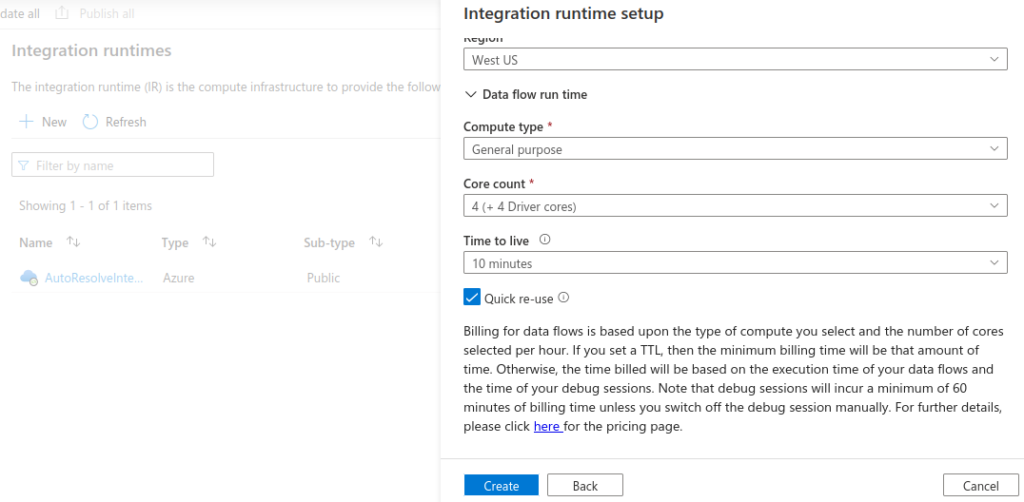
Ensure that you select appropriate Data flow run time settings; Compute type, Core count and Time to live (TTL). The TTL setting and Quick re-use checkbox allows to reduce cluster startup time