Software containerization is the modern application programming model that has revolutionized the present day enterprise application development. It not only helps to make the application portable but also makes it scalable, I recently added a post that describes building GraphQL service as a containerized application. The main component of a containerized application is the orchestration engine, Kubernetes. Each major cloud provider has the managed Kubernetes service to provide production ready environment, Google Kubernetes Engine (GKE) is the service available on the Google cloud platform (GCP). Google provides the GKE standard and autopilot modes, autopilot is the fully managed service. This post describes the most useful features of Google Kubernetes Engine Autopilot required to implement an enterprise application
Prerequisites
- Understanding of containerized application architecture
- Basic understanding of Kubernetes
- Experience with GCP and GCP services such as GKE, IAM, Cloud storage, Cloud SQL, etc.
Reference Architecture
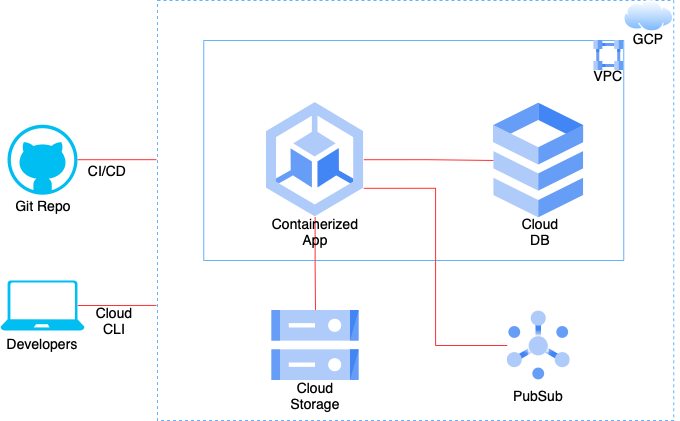
We will refer to the above architecture to understand the Google Kubernetes Engine Autopilot features. The diagram is simplified to include the most common components. An enterprise containerized application on GCP is deployed on GKE. It most commonly interfaces with other GCP services such as cloud storage, pubsub and cloud database. Also, a source code repository hosted on a managed git instance connects to GCP as a part of CI/CD setup. And development team members interact with the GCP services using cloud cli. If you want to understand different aspects of an enterprise application project structure including CI/CD, please refer to my recent post
1. Private cluster
Security is the key consideration for any enterprise application, especially hosted on a cloud infrastructure. A virtual private network (VPC) service on GCP allows to secure compute, database and other resources from any outside accesses. A private GKE Autopilot cluster, created in a VPC, is accessible only inside the company network. The nodes created by the private cluster will be in the private network hence making the containerized application more secure
gcloud container clusters create-auto private-cluster-1 \
--region us-central1 \
--enable-master-authorized-networks \
--network my-net \
--subnetwork my-subnet \
--cluster-secondary-range-name my-pods \
--services-secondary-range-name my-services \
--enable-private-nodesCode language: PHP (php)The above cli command creates a private autopilot cluster with limited access to the public endpoint. The GKE endpoint is used for the cluster management. This endpoint can also be kept completely private. However, that will require additional network setup between GCP and your enterprise resources such as source control and development machines. The private cluster with limited access to the public endpoint will help you to achieve extra security with limited setup. With the authorized networks, you can white list IPs to access the public endpoint, e.g. CI/CD server, source control server, developer machine, etc.
gcloud container clusters update private-cluster-1 \
--master-authorized-networks XXX.XXX.XXX.XXX/YYCode language: PHP (php)2. Service account and role-based access control
Service account and role-based access control (RBAC) allows to grant granular permissions to objects within the cluster. There is a namespaced grouping of resources called Role and a cluster-level grouping of resources called ClusterRole. If you are working on an application using GKE, it will require you to create a service account and bind it to either Role or ClusterRole or both. For example, if the application schedules jobs then the service account will require a Role that allows to create, list and delete pods. And if the application modifies persistent volume (pv) then the service account will require a ClusterRole that allows to create, list and delete pv
3. Workload identity
While service account and RBAC is for the access control within cluster, workload identity is the recommended way for the workloads running on GKE to access Google Cloud services in a secure and manageable way. Workload Identity allows a service account in your GKE cluster to act as an IAM service account so that it can access GCP services such as cloud storage, pubsub, etc. In the reference architecture above, the application on GKE interfaces with cloud storage and pubsub which will require workload identity. Autopilot clusters enable Workload Identity by default. Follow the steps at this link to enable your application to use workload identity
4. IP masquerading and Egress NAT policy
IP masquerading is a form of source network address translation (SNAT) used to perform many-to-one IP address translations. GKE uses IP masquerading to change the source IP addresses of packets sent from pods so that recipients can see the packets from the pods as if received from the nodes. This is a very important feature because various resources on a corporate network receive traffic only from specific IP ranges due to security reasons. In the reference architecture, the application is on a private network and it connects to source code repository in the same corporate network. Unless the pod IP range is in the corporate network, the cluster will require the pod to emit data packets with node IP instead of pod IP for the connectivity. GKE Autopilot cluster creates default Egress NAT policy with set of non-masquerade IP ranges
kubectl edit egressnatpolicies defaultCode language: JavaScript (javascript) apiVersion: networking.gke.io/v1
kind: EgressNATPolicy
metadata:
name: default
spec:
action: NoSNAT
destinations:
- cidr: 10.0.0.0/8
- cidr: 172.16.0.0/12
- cidr: 192.168.0.0/16
- cidr: 240.0.0.0/4
- cidr: 192.0.2.0/24
- cidr: 198.51.100.0/24
- cidr: 203.0.113.0/24
- cidr: 100.64.0.0/10
- cidr: 198.18.0.0/15
- cidr: 192.0.0.0/24
- cidr: 192.88.99.0/24Code language: JavaScript (javascript)Let’s assume that your source code repository server IP falls in any of these ranges. You will need to modify these ranges to allow IP masquerading agent to send node IP instead of pod IP to that server
5. In-cluster configuration
Imagine that you need to automate certain aspects of the GKE cluster from your containerized application deployed on the cluster. The recommended way to achieve that is using official Kubernetes client API libraries. The client API requires authentication to connect to the cluster. The in-cluster configuration helps when accessing the API from within a pod
from kubernetes import client, config
def main():
config.load_incluster_config()
v1 = client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\t%s\t%s" %
(i.status.pod_ip, i.metadata.namespace, i.metadata.name))
if __name__ == '__main__':
main()Code language: JavaScript (javascript)The code (Python3) snippet above shows the steps to access the cluster resources using K8 client API. Using the API, you can automate and control your cluster from your containerized application